
The rise of generative AI means that huge archives of photographs and videos are suddenly valuable with the current situation being compared to a gold rush, but which platforms are licensing their content to large tech firms for the purposes of training AI models?
Different companies have different deals: Shutterstock, for example, licenses content to external AI companies, while others like Getty Images use content from its own platform to build in-house generative AI models.
This is controversial because when contributors signed up to these platforms, they didn’t expect or consent to their work being used in such a way.
Despite AI companies such as Midjourney, OpenAI, and Stability AI being strongly rumored to have done a huge scrape of all content on the open web to build their models, high-quality imagery is crucial if these companies want to continue adding to their products and building new ones.
Cloak and Dagger
Some photo platforms don’t want it known that they are making these types of deals with AI companies, which is why PetaPixel has made a list of all of the companies that have — or are rumored to have — deals with AI firms. Yesterday, U.S. congressman Adam Schiff introduced a bill that would require AI companies to reveal what data they use to train models with.
Many photographers will be interested to know what their content is being used for outside of being displayed on the platform of their choice and we hope this article can act as a resource for creatives concerned about this rapidly growing market.
Facebook and Instagram
I would wager photographers upload pictures to Meta’s platforms, particularly Instagram, more than any other. As far as we know, Meta does not give training consent to any outside AI firms but that’s because Meta is building its own generative AI tools.
During his earnings call for Meta’s fourth quarter results in February, Mark Zuckerberg made it clear he will use images posted on Facebook and Instagram to train his generative AI tools with.
“When people think about data, they typically think about the corpus that you might use to train a model up front,” Zuckerberg said.
“On Facebook and Instagram, there are hundreds of billions of publicly shared images and tens of billions of public videos, which we estimate is greater than the Common Crawl dataset and people share large numbers of public text posts in comments across our services as well.”
So, if you’re uploading a photo to Instagram or Facebook, there is every chance it will be used to train Meta’s AI image generator.
Shutterstock
Shutterstock has been a market leader in stock photography for many years and it has also been one of the early AI adopters. It has built its own AI image generator but it has also struck deals with Meta, Google, Amazon, and Apple to license hundreds of millions of images from its library for training purposes, according to a Reuters report.
The news agency reports that those deals are in the region of $25 to $50 million each but the specifics haven’t been made public.
Shutterstock has an AI contributor fund which it may have paid out $4 million from, according to a report last summer.
Tumblr
Tumblr is a good example of a platform that has fallen in popularity in recent years but is now looking to cash in on the AI boom — but doesn’t want anyone to know about it.
In February, a report from 404 Media said Tumblr was in the process of striking a deal with OpenAI and Midjourney to license its content.
Exactly what type of content is a mystery but if Midjourney is involved then it is likely to include images. The report came from an anonymous employee inside Tumblr which is owned by Automattic and also owns WordPress.com.
The blogging platform will give users a way of opting out but there are reports that the company already scraped all public posts between 2014 and 2023.
EyeEm and Freepik
EyeEm was purchased by Freepik in 2023 and a recent letter to EyeEm contributors informed them that an update to its Terms & Conditions means the company now has the right to license contributor photos for AI training purposes.
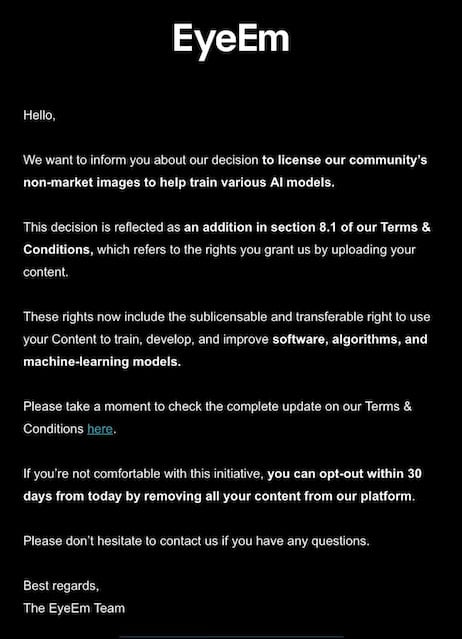
EyeEm says contributors can opt out of this but didn’t mention if there would be payment for this type of licensing. But in a Facebook comment to a disgruntled contributor, EyeEm wrote “You will get compensated with the usual 50/50 share. We’re building the reporting to support this.”
Meanwhile, EyeEm’s parent company Freepik told Reuters that it has signed agreements with two large tech firms to license the majority of its archive of 200 million images at around 3 cents per image. CEO Joaquin Cuenca Abela said there are five more similar deals in the works but declined to identify the buyers.
Getty Images and iStock
Despite making a stand against Stable Diffusion, accusing the AI image generator of using 12 million photos without consent, Getty launched Generative AI by Getty Images powered by NVIDIA as well as Generative AI by iStock, an AI image generator that allows customers to create their own AI stock photos.
Getty says both models were “trained exclusively using high-quality content and proprietary data from Getty Images’ creative libraries.”
The photo agency says it has set up a contributor payment system that will pay photographers if their work has been used in the training data. The company stresses it is taking a “responsible” approach to copyright.
Adobe
Adobe has been praised for building its AI model in “the right way.” Its Firefly AI image model was built exclusively on Adobe Stock images, openly licensed content, and public domain works.
But in January there was a brouhaha after Adobe added a “Content Analysis” section to its privacy and personal data collection permissions, leaving some wondering whether Adobe was helping themselves to images on Creative Cloud. However, the company behind Photoshop insisted that it is not using photographers’ photos to train AI.
Photobucket
PetaPixel reported that Photobucket is in talks with AI firms to license its contents for the purposes of training algorithms.
CEO Ted Leonard told Reuters that he is in talks with “multiple tech companies” to license the website’s 13 billion photos and videos. He has discussed rates of 5 cents to $1 per photo and over $1 per video with prices varying depending on the buyer and the types of imagery they are seeking. He declined to reveal the identity of the potential buyers.
Flickr
There are no reports about Flickr licensing its vast pool of content to AI firms but given Flickr’s visibility on the open web and that it includes tags describing the photos, there is a strong chance that images on there have already been used for AI training without Flickr’s consent. PetaPixel has reached out for comment.
A deal reportedly worth $60 million per year gives Google real-time access to Reddit’s data but it’s unclear whether that is just text or includes pictures. Both Reddit and Google have so far declined to comment on the arrangement but PetaPixel reached out to Reddit for clarification.