

Chinese multinational Alibaba, best known for its e-commerce operations, also heavily invests in technological development projects. Researchers in the company’s Institute for Intelligent Computing showed off their new AI video generator, EMO.
EMO, or Emote Portrait Alive, is an “expressive audio-driven portrait-video generation framework” that turns a single still reference image and vocal audio into an animated avatar video with facial expressions and poses.
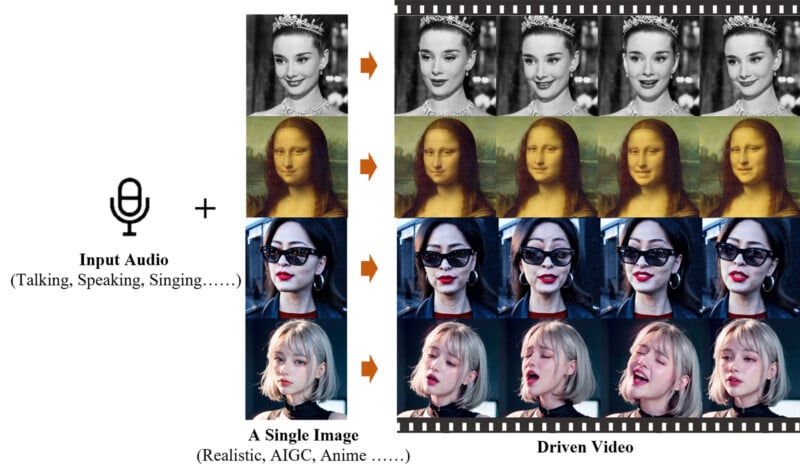
Among the numerous examples the team created is taking a still AI-generated sunglasses-wearing woman from OpenAI’s Sora debut and having her sing “Don’t Start Now” by Dua Lipa. Fortunately, the character is one of the least terrifying of Sora’s creations.
Another example shows an AI-generated photo of da Vinci’s Mona Lisa and having her sing “Flowers” by Miley Cyrus, as covered by YUQI. In another clip, Audrey Hepburn sings a cover of an Ed Sheeran track. The YouTube channel RINKI compiled all of Alibaba’s demo clips and upscaled them to 4K.
A critical part of EMO is that it can sync lips in a synthesized video clip with real audio, so importantly, the model supports songs across multiple languages. It also works with numerous artistic styles, whether photograph, painting, or anime-style cartoon. It also works with other audio inputs, like typical speech.
Theoretically, an audio input wouldn’t have to be “authentic,” either. Just this week, Adobe showed off a new generative AI platform that can create music from text prompts. And as celebrities like Taylor Swift know all too well, it’s very straightforward for people to generate realistic-sounding voices.
The model, built on a Stable Diffusion backbone, is not the first of its kind but arguably the most effective. There are noticeable imperfections in this initial effort, including a rather heavy softening effect on people’s skin and occasionally jarring mouth movements. Still, the overall accuracy of the lip movements in response to the input audio is remarkable.
The Alibaba Institute for Intelligent Computing’s complete research is published on Github, and the associated research paper is available on ArXiv.
Image credits: “Emote Portrait Alive: Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions” by LinRui Tian, Qi Wang, Bang Zhang, and LieFeng Bo